
Accurately estimating depth in 360-degree imagery is crucial for virtual reality, autonomous navigation, and immersive media applications. Existing depth estimation methods designed for perspective-view imagery fail when applied to 360-degree images due to different camera projections and distortions, whereas 360-degree methods perform inferior due to the lack of labeled data pairs. We propose a new depth estimation framework that utilizes unlabeled 360-degree data effectively. Our approach uses state-of-the-art perspective depth estimation models as teacher models to generate pseudo labels through a six-face cube projection technique, enabling efficient labeling of depth in 360-degree images. This method leverages the increasing availability of large datasets. Our approach includes two main stages: offline mask generation for invalid regions and an online semi-supervised joint training regime. We tested our approach on benchmark datasets such as Matterport3D and Stanford2D3D, showing significant improvements in depth estimation accuracy, particularly in zero-shot scenarios. Our proposed training pipeline can enhance any 360 monocular depth estimator and demonstrates effective knowledge transfer across different camera projections and data types.
This gallery presents the in-domain qualitative improvements using backbone models (UniFuse and BiFuse++) trained on the Matterport3D training set and evaluated on the test set.
The gallery is organized as follows:
(Top) Input/GT,
(Mid) Depth Map Comparison between SOTA and SOTA+Ours,
(Bottom) Error Map Comparison between SOTA and SOTA+Ours.
+Ours indicates the use of the pseudo ground truth training pipeline proposed in our methods.


























This gallery presents the zero-shot qualitative improvements using backbone models (UniFuse and BiFuse++) trained on the entire Matterport3D dataset and evaluated on the Stanford2D3D test set.
The gallery is organized as follows: (Top) Input/GT,
(Mid) Depth Map Comparison between SOTA and SOTA+Ours,
(Bottom) Error Map Comparison between SOTA and SOTA+Ours.
+Ours indicates the use of the pseudo ground truth training pipeline proposed in our methods.
























This gallery presents the zero-shot in-the-wild qualitative improvements using a combination of images captured by us and randomly sourced from the internet
[1]
to assess the model’s generalization ability.
For privacy reasons, we have obscured the camera-man in the images.
The gallery is organized as follows:
(Top) Input/SOTA+Ours,
(Bottom) Depth Map Comparison between SOTA and SOTA+Ours,
+Ours indicates the use of the pseudo ground truth training pipeline proposed in our method.
The SOTA model demonstrated here is UniFuse.













Our proposed training pipeline involves joint training on both labeled 360 data with ground truth and unlabeled 360 data. (a) For labeled data, we train our 360 depth model with the loss between depth prediction and ground truth. (b) For unlabeled data, we propose to distill knowledge from a pre-trained perspective-view monocular depth estimator. In this paper, we use Depth Anything to generate pseudo ground truth for training. However, more advanced techniques could be applied. These perspective-view monocular depth estimators fail to produce reasonable equirectangular depth as there exists a domain gap. Therefore, we distill knowledge by inferring six perspective cube faces and passing them through perspective-view monocular depth estimators. To ensure stable and effective training, we propose generating a valid pixel mask with Segment Anything while calculating loss. (c) Furthermore, we augment random rotation on RGB before passing it into Depth Anything, as well as on predictions from the 360 depth model.
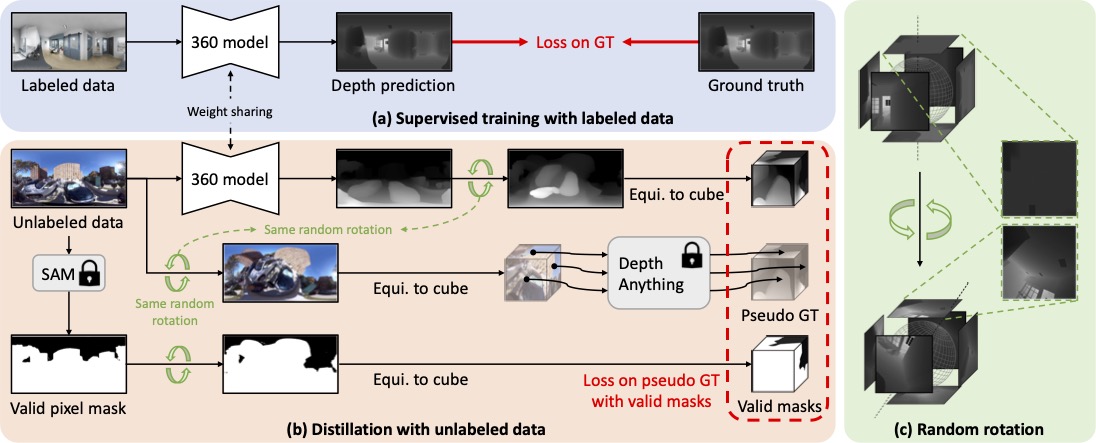
We used Grounded-Segment-Anything to mask out invalid pixels based on two text prompts: “sky” and “watermark.” These regions lack depth sensor ground truth labels in all previous datasets. Unlike Depth Anything, which sets sky regions as 0 disparity, we follow ground truth training to ignore these regions during training for two reasons: (1) segmentation may misclassify and set other regions as zero, leading to noisy labeling, and (2) watermarks are post-processing regions that lack geometrical meaning.

As shown in the center row of the figure, an undesired cube artifact appears when we apply joint training with pseudo ground truth from Depth Anything directly. This issue arises from independent relative distances within each cube face caused by a static point of view. Ignoring cross-cube relationships results in poor knowledge distillation. To address this, as shown in (c) in the model pipeline, we randomly rotate the RGB image before inputting it into Depth Anything. This enables better distillation of depth information from varying perspectives within the equirectangular image.

Refer to the pdf paper linked above for more details on qualitative, quantitative, and ablation studies.
@article{wang2024depth,
title={Depth anywhere: Enhancing 360 monocular depth estimation via perspective distillation and unlabeled data augmentation},
author={Wang, Ning-Hsu Albert and Liu, Yu-Lun},
journal={Advances in Neural Information Processing Systems},
volume={37},
pages={127739--127764},
year={2024}
}